User Tags
User tags offer the capability to extract specific portions of incoming messages as metadata. Once extracted, this metadata can then be leveraged throughout the LogZilla system. Here are some of the primary applications and benefits of using User Tags:
-
Enhance Visibility: User tags can accentuate specific logs or events, ensuring they stand out, especially within a dense dashboard. This highlighting is particularly useful during critical incidents or when monitoring specific parameters.
-
Improve Organization: By applying user tags, logs and events can be grouped based on common criteria. This organization fosters a more structured and user-friendly dashboard layout, making data interpretation quicker and more intuitive.
-
Customize Data Views: Personalization is at the heart of user tags. Users have the autonomy to design dashboard views that spotlight only the tagged data points they deem essential, filtering out potential noise.
-
Narrow Down Results: Searching within a vast dataset can be challenging. However, by inputting a specific tag into the search query, users can concentrate the results, displaying only those logs or events associated with the chosen tag. This precision drastically reduces the time spent searching.
-
Speed Up Searches: Efficiency is crucial, especially in real-time monitoring. Tag-based searches expedite the search process by sidestepping irrelevant data, offering users the results they need without delay.
-
Create Complex Queries: For those situations requiring a more detailed search, user tags can be amalgamated with other search criteria. This fusion enables users to devise intricate search queries, tailored to fetch exact data subsets.
-
Apply Precision Filters: Filtering is an essential tool in data management. With user tags, users can employ sharp, precise filters, ensuring the display of only the most relevant logs or events.
-
Combine with Other Filters: User tags are versatile and can be melded with other filtering criteria. This integration results in a comprehensive filtering experience, catering to even the most specific data needs.
-
Set Up Alerts: Being promptly informed can make all the difference. With user tags, the system can be configured to dispatch email alerts when particular tagged events transpire, ensuring users are always in the loop.
Extracting Insight From Arbitrary Data
LogZilla’s User Tags facilitate the extraction and transformation of any arbitrary data from incoming events, granting users the ability to derive valuable insights from a variety of metrics. These metrics include:
- Device types
- Users
- Locations
- GeoIP
- Authentication Failures
- Audit Log Tracking
- Malware Types/Sources/Destinations
The scope of what can be captured through User Tags extends well beyond this list, given LogZilla’s rule parser capabilities. Essentially, “User Tags” enable the extraction and tracking of any information that can provide insights into daily operations across NetOps, SecOps, DevOps, and other operational domains.
Consider the incoming events:
%AUTHPRIV-3-SYSTEM_MSG: pam_aaa:Authentication failed for user bob from 10.87.8.1
Log-in failed for user 'agents' from 'ssh'
From these logs, one might want to extract and monitor the usernames and their source addresses:
- Create a rule named
100-auth-fail-tracking.yaml - Incorporate the desired pattern match and user tag
- Configure the rule to label this event as
actionable(it’s worth noting that statuses can also be designated asnon-actionable).
rewrite_rules:
-
comment: "Auth Fail User Tracking"
match:
field: "message"
op: "=~"
value: "for (?:user)? '?([^\\s']+)'? from '?([^\\s']+)'?"
tag:
Auth Fail User: "$1"
Auth Fail Source: "$2"
rewrite:
status: "actionable"
- Incorporate the new rule using
logzilla rules add 100-auth-fail-tracking.yaml - Add a
TopNwidget to any dashboard (e.g.,Top Hosts) and modify that widget to select the newly created user tag field, combined with other widget filters, such as “Program” set to specific sources like “Cisco”:
User Tags Field Selector
- The
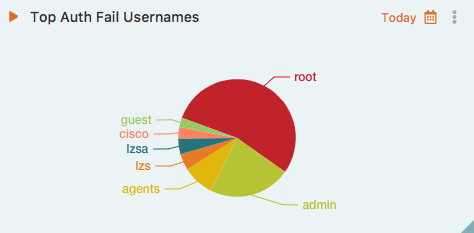
TopNchart will subsequently display the top 5 Client Usernames.
Top Auth Fail Usernames chart
Match/Update Based on Previously Created Tags
LogZilla also provides the functionality to set custom tags and subsequently use those tags within the same or different rule files. If utilizing a tag-based match/update, it is imperative to generate the tag beforehand.
For instance:
001-cisco-acl.yaml - Construct the tag based on a message match:
rewrite_rules:
-
comment:
- "Extract denied List Name, Protocol and Port Numbers from Cisco Access List logs"
- "Sample Log: Oct 4 22:33:40.985 UTC: %SEC-6-IPACCESSLOGP: list PUBLIC_INGRESS denied tcp 201.166.237.25(59426) -> 212.174.130.30(23), 1 packet"
match:
field: "message"
op: "=~"
value: "list (\\S+) denied (\\S+) \\d+\\.\\d+\\.\\d+\\.\\d+\\((\\d+)\\).+?\\d+\\.\\d+\\.\\d+\\.\\d+\\((\\d+)\\)"
tag:
Deny Name: "$1"
Deny Protocol: "$2"
Deny Source Port: "$3"
Deny Dest Port: "$4"
002-port-to-name.yaml - Utilize the tag established in
001-cisco-acl.yaml to map port numbers to their respective names:
first_match_only: true
rewrite_rules:
-
comment: "Match on previously created Cisco ACL tags and convert the port numbers extracted stored in that same tag to a name for ports 22, 23, 80 and 443"
match:
field: "Deny Dest Port"
value: "22"
tag:
Deny Dest Port: "ssh"
-
match:
field: "Deny Dest Port"
value: "23"
tag:
Deny Dest Port: "telnet"
-
match:
field: "Deny Dest Port"
value: "80"
tag:
Deny Dest Port: "http"
-
match:
field: "Deny Dest Port"
value: "443"
tag:
Deny Dest Port: "https"
Example 2
The following example assumes that a previous rule file (or even an
earlier rule in the same file) has already created the SU Sessions
user tag.
The rule below instructs the system to match on SU Sessions and set
the program to su. However, this action is only performed if the
matched
value does not equate to an empty string (blank messages).
rewrite_rules:
-
comment: "Track su sessions"
match:
field: "SU Sessions"
op: "ne"
value: ""
rewrite:
program: "su"
Makemeta
A helper script located on our GitHub is available to be used to create rules automatically using a tab separated file as input. You can download the script here
Input fields
The .tsv (tab-separated-values) file must contain at least 6 columns
Columns 1-4
Columns 1-4 must be:
For exampleColumn 1
Indicates whether or not (0 or 1) a user tag should also be created for this entry
Column 2
The string you want to match on, for example: my.host.com or foo bar baz
Column 3
The field to match on in LogZilla, such as host, program, message, etc.
Column 4
Defines the match Operator to use. Options are:
| Operator | Match Type | Description |
|---|---|---|
| eq | String or Integer | Matches entire incoming message against the string/integer specified in the match condition |
| ne | String or Integer | Does not match anything in the incoming message match field. |
| gt | Integer Only | Given integer is greater than the incoming integer value |
| lt | Integer Only | Given integer is less than the incoming integer value |
| ge | Integer Only | Given integer is greater than or equal to the incoming integer value |
| le | Integer Only | Given integer is less than or equal to the incoming integer value |
| =~ | RegEx | Match based on RegEx pattern |
| !~ | RegEx | Does not match based on RegEx pattern |
| =* | RegEx | RegEx appears anywhere in the incoming message |
Columns 5 and greater
All columns after column 4 are key-value pairs to be added. For example, given the following entire row in a file:
1 10.1.2.3 host eq deviceID rtp-core-sw DeviceDescription RTP Core Layer2 DeviceImportance High DeviceLocation Raleigh DeviceContact [email protected]
key="value" pairs, like so:
Key = DeviceImportance, value = High
Key = DeviceDescription, value = RTP Core Layer2
Key = DeviceLocation, value = Raleigh
Key = deviceID, value = rtp-core-sw
Key = DeviceContact, value = [email protected]
1 10.1.2.3 host eq deviceID rtp-core-sw DeviceDescription RTP Core Layer2 DeviceImportance High DeviceLocation Raleigh DeviceContact
This would produce errors when the perl script runs, e.g.:
Odd number of elements in hash assignment at ./makemeta line 60, <$fh> line 4.
Use of uninitialized value $kvs{"DeviceContact"} in string comparison (cmp) at ./makemeta line 78, <$fh> line 4.
Use of uninitialized value $kvs{"DeviceContact"} in string comparison (cmp) at ./makemeta line 78, <$fh> line 4.
Use of uninitialized value $kvs{"DeviceContact"} in string comparison (cmp) at ./makemeta line 78, <$fh> line 4.
Use of uninitialized value $kvs{"DeviceContact"} in string eq at ./makemeta line 80, <$fh> line 4.
Usage
./makemeta
Usage:
makemeta
-debug [-d] <1 or 2>
-format [-f] (json or yaml - default: yaml)
-infile [-i] (Input filename, e.g.: test.tsv)
Sample test.tsv file:
1 <TAB> host-a <TAB> host <TAB> eq <TAB> deviceID <TAB> lax-srv-01 <TAB> DeviceDescription <TAB> LA Server 1
User Tags
If column 1 on your .tsv contains a 1, user tags will also be created for every key/value pair. As such, you will now see these fields available in your widgets. For example, the following rule:
- match:
- field: host
op: eq
value: host-a
tag:
metadata_importance: High
metadata_roles: Core
metadata_locations: Los Angeles
update:
message: $MESSAGE DeviceDescription="LA Server 1" DeviceLocation="Los Angeles" DeviceImportance="Low" deviceID="lax-srv-01" DeviceContact="[email protected]"
- match:
- field: message
op: =~
value: down
update:
message: $MESSAGE DeviceImportance="Med" DeviceDescription="NYC Router" DeviceLocation="New York" deviceID="nyc-rtr-01" DeviceContact="[email protected]"
Will produce fields available similar to the screenshot below:
Screenshot: Available Fields

Caveats/Warnings
-
Tag names are free-form allowing any alphabetic characters. Once a message matches the pattern, the tag is automatically created in the API, then made available in the UI. If a tag is created but does not show up in the UI, it may simply mean there have been no matches on it yet. (note: users may want to try a browser refresh to ensure a non-cached page is loaded).
-
Any
_'s in the tag name will be converted to aspace characterwhen displayed in the UI. -
Tagging highly variable data may result in degradation or even failure of metrics tracking (not log storage/search) based on the capability of your system. This is due to cardinality limitations in InfluxDB. The following article outlines this limitation in more detail.
NOTE: certain user tag names are reserved for LogZilla internal use, and
cannot be used as user tags; in these cases you will need to choose an
alternative (a simple option would be to prefix the field name with ut_).
The reserved names are:
* first_occurrence
* last_occurrence
* counter
* message
* host
* program
* cisco_mnemonic
* severity
* facility
* status
* type
CAUTION: Care should be taken to keep the number of tags below 1m entries per tag.
Tag Performance
Performance, especially in data-intensive environments, is paramount. When manipulating large streams of data, the potential for performance degradation increases. Several factors can contribute to performance dips, including CPU limitations, Memory constraints, Disk I/O, and the manner in which rules are presented to the parsing engine.
Ensuring Good Rule Performance
Crafting large rulesets often demands a thoughtful approach to
performance. One strategy is the use of a precheck match. Before
delving into complex regular expression matches, it’s advisable to use a
preliminary string match. In this context, the term precheck doesn’t
refer to a specialized type; it’s essentially the same syntax as a
match type. However, instead of using the regex-based =~, it uses
the string match eq. This preliminary check ensures that generic regex
patterns don’t mistakenly match unintended messages.
Consider the following example:
Sample “pre-match”
rewrite_rules:
- comment:
- 'Vendor: HP Aruba'
- 'Type: Hardware'
- 'Category: 802.1x'
- 'Description: This log event informs the number of auth timeouts for the last known time for 802.1x authentication method.'
- 'Sample Log: <NUMBER_OF> auth-timeouts for the last <TIME> sec.'
match:
- field: message
op: eq
value: auth-timeouts for the last
- field: message
op: =~
value: \S+ auth-timeouts \S+ \S+ \S+ \S+ sec .*
rewrite:
program: HP_Switch
tag:
category: 802.1x
type: hardware
vendor: HP
Bad Regex
Crafting efficient regex is vital. When dealing with thousands of rules,
the efficiency of each regex pattern can substantially impact
performance. Referring to the earlier example, it’s evident that a
prematch isn’t strictly necessary (it’s used primarily for
demonstration). A more efficient approach would skip the prematch and
employ an optimized regex pattern like
\\S+ auth-timeouts for the last \\S+ sec.
For best results, use tools like RegEx101 to validate regex patterns and assess their efficiency.
Testing
LogZilla provides a command-line utility, logzilla rules, that offers
a suite of functionalities:
- list - List rewrite rules
- reload - Reload rewrite rules
- add - Add rewrite rule
- remove - Remove rewrite rule
- export - Save rule to file
- enable - Enable rewrite rule
- disable - Disable rewrite rule
- errors - Display rules with errors, including counts
- performance - Assess single thread performance of rules
- test - Verify the validity and correct operation of a rule
To incorporate your rule, simply execute:
logzilla rules add myfile.yaml
Tag Naming
Tag names in LogZilla are free-form, accommodating any alphabetic characters. When a message matches a specified pattern, the corresponding tag is instantly created in the API and subsequently becomes accessible in the UI. If a tag doesn’t appear in the UI, it might indicate that no matches have been found for it yet. Refreshing the browser can help display the most recent changes.
LogZilla’s recommended approach to user tag naming falls under two main categories. The first category encompasses the most common data fields typically found in event log messages:
| User Tag | Example | Meaning |
|---|---|---|
SrcIP |
127.0.0.1 |
Source IPv4 address |
SrcIPv6 |
2001:0db8:85a3:0000:0000:8a2e:0370:7334 |
Source IPv6 address |
DstIP |
11.22.33.44 |
Destination IPv4 address |
DstIPv6 |
2001:0db8:85a3:0000:0000:8a2e:0370:7334 |
Destination IPv6 address |
SrcPort |
dynamic |
Source port (descriptive abbreviation or dynamic if unspecified) |
DstPort |
https |
Destination port (descriptive abbreviation or dynamic if unspecified) |
Proto |
TCP |
Communications protocol (typically TCP, UDP, or ICMP) |
MAC |
00:00:5e:00:53:af |
MAC address |
IfIn |
enp8s0 |
Interface in |
IfOut |
enp8s0 |
Interface out |
The second category pertains to all other tags not listed above. These tag names usually mirror the vendor field names. This approach ensures that individuals familiar with specific vendor log messages can seamlessly identify corresponding LogZilla user tags:
| Vendor Field and User Tag | Meaning |
|---|---|
act |
Action taken |
cat |
Category |
cnt |
Count |
dhost |
Destination host |
dvchost |
Device host |
By maintaining consistency with vendor field names, LogZilla enhances the user experience and ensures a smooth transition for those accustomed to vendor-specific terminologies.
Caveats/Warnings
LogZilla’s User Tags bring flexibility and power to data management, but users should be mindful of certain caveats and warnings to ensure optimal system performance and prevent unintended results:
- Cardinality Concerns with InfluxDB: Tagging data that varies significantly can sometimes lead to performance degradation or even metrics tracking failures. This limitation arises due to cardinality constraints inherent in InfluxDB. For a deeper understanding of this issue, consider reading this detailed article.
CAUTION: It’s critical to exercise caution when dealing with tags. Ensure that the number of entries for any single tag remains below 1 million to avoid potential system strain or inefficiencies.